Nube de noticias de Europa Press ordenada por un algoritmo de Inteligencia Artificial - EUROPA PRESS
MADRID, 20 Sep (EUROPA PRESS) -
¿Puede la inteligencia artificial ayudar a los periodistas a detectar y combatir el aumento de las 'fake news'? Ese es precisamente el objetivo del nuevo proyecto de I+D de Europa Press que está desarrollando junto a AyGLOO. Este proyecto cuenta con el apoyo financiero del Centro para el Desarrollo Tecnológico Industrial (CDTI) y en él se van a crear herramientas de análisis y detección rápida de noticias falsas que además expliquen los motivos por los que son consideradas falsas.
¿A qué problema nos enfrentamos?
Una predicción hecha por la consultora Garnet en 2017 ponía el foco en 2022 y afirmaba que para ese año el público occidental consumiría más noticias falsas que verdaderas. No existe manera de comprobar si ya hemos cruzado ese umbral, pero la preocupación por el aumento de las 'fake news' se ha situado en el centro del debate público.
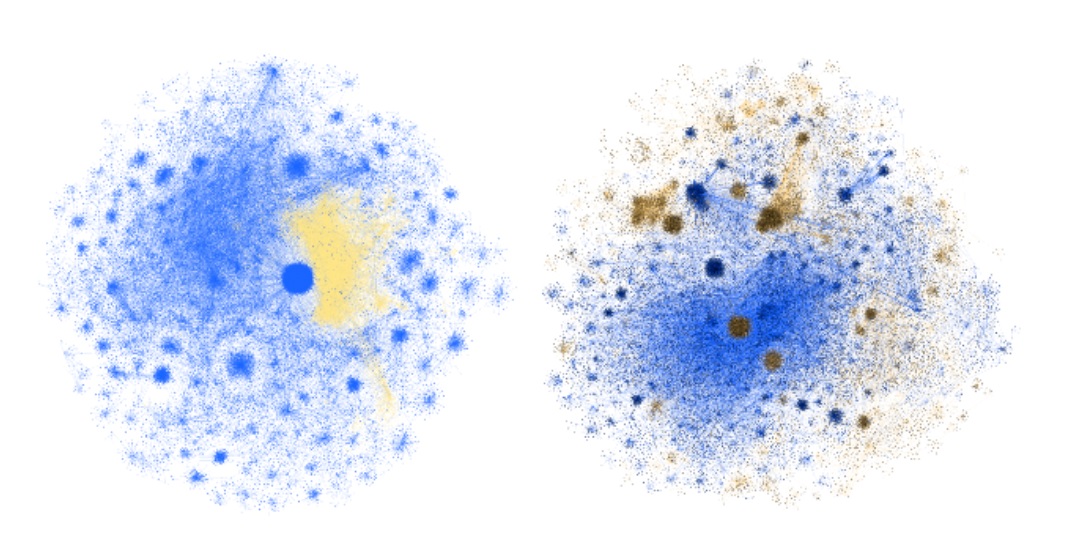
Un estudio de la Universidad de Indiana muestra cómo se propagan las noticias falsas (en amarillo / marrón) a través de contactos de Twitter. Fuente.
Según el Ministerio de Asuntos Exteriores, Unión Europea y Cooperación, los bulos y la desinformación representan "una amenaza global para la libertad y para la democracia" que se ha agravado debido a las redes sociales y a que "en los últimos años se ha acelerado tanto el flujo de información como el de desinformación", como se ha demostrado con la pandemia del COVID. Una realidad que empeora teniendo en cuenta estudios que apuntan a que ocho de cada diez españoles tiene dificultades para distinguir entre noticias falsas y verdaderas.
¿Quiénes somos?
La Comisión Europea ha señalado que en la lucha contra la desinformación resulta clave la coordinación de tres actores: las empresas tecnológicas, la sociedad civil (incluyendo factcheckers), y las instituciones académicas.
Aunar la experiencia de un medio de comunicación en el sector informativo y el conocimiento de expertos en Inteligencia Artificial es precisamente el núcleo del nuevo proyecto de Europa Press, que incluye al grupo de desarrolladores de Europa Press, el equipo de Data Scientists, arquitectos de sistemas y programadores de AyGLOO y la colaboración de la Universidad Politécnica de Madrid, y a GIATEC.
¿Dónde queremos llegar?
El objetivo final es dotar a los redactores de Europa Press y otros medios interesados de herramientas capaces de agilizar el proceso de la verificación de noticias. ¿Cómo? Con la aplicación de técnicas avanzadas de inteligencia artificial capaces de analizar el texto de la noticia y avisar al redactor o bien de que esa noticia ya ha sido verificada por otro organismo independiente o bien, cuando sea necesario, de que es sospechosa de ser falsa y debe ser verificada por un experto. Un sistema de alerta temprana que podría usarse como primer 'test' ante un texto difundido en redes sociales, foros u otros ámbitos de Internet.
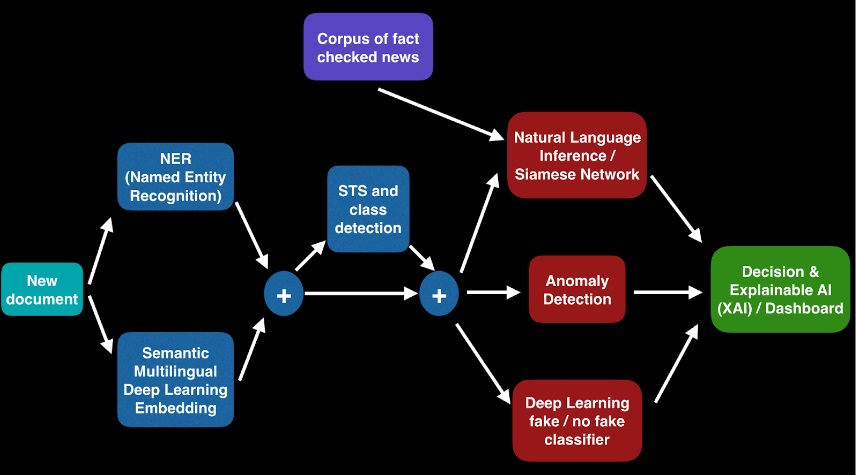
Diagrama que muestra los pasos que seguirá la herramienta de alerta temprana de fake news.
El Smart Fake News Detection (FND), como se llama la herramienta, estará caracterizado por encadenar varias técnicas diferentes de inteligencia artificial sobre el texto de la noticia objeto de análisis como el NLP (Procesamiento de Lenguaje Natural), STS (Similaridad Semántica de textos), NLI (Inferencia de Lenguaje Natural), Detección de Anomalías, y XAI (Inteligencia Artificial Explicable). El resultado de la herramienta será finalmente presentado en un cuadro de mandos de validación, clasificación y explicación.
Para detectar si una notifica es falsa o no, cada texto noticioso pasará por una secuencia de procesos de inteligencia artificial con aprendizaje profundo que tratan el texto en una cascada de pasos (categorización y etiquetado, vectorización semántica / embedding, búsqueda de similitudes, inferencia, clasificación), que finalmente determinarán su veracidad.
Todos estos tratamientos siguen un proceso en paralelo de inteligencia artificial explicable (XAI) para poder mantener la transparencia y confianza en el proceso seguido por nuestra herramienta FND.
Nube de noticias que representa la cercanía o lejanía semántica entre noticias. Cada punto es una noticia. Cada color representa un tipo de noticia identificada por el algoritmo de IA.
¿En qué punto estamos?
El proyecto comenzó a principios de 2022 y ya se ha completado el primer paso de ese proceso: el análisis de lenguaje natural (NLP), encargado de categorizar la noticia y un análisis NER (Named-Entity Recognition), para detectar y etiquetar entidades dentro de la noticia.
Para ello, partiendo de un dataset de miles noticias de Europa Press, se entrenó un sistema donde primero se extrae mediante una red neuronal profunda de tipo transformer la codificación semántica del documento (un vector con 512 componentes), y luego se clasifica este vector en una de las categorías mediante una red neuronal avanzada. Las categorías asignadas por la red no coinciden muchas veces con las asignadas por Europa Press ya que hay noticias que pueden clasificarse en varias secciones. Por ejemplo, hay noticias que pueden etiquetarse como Educación o Sociedad, y hay otras que pueden etiquetarse como Motor o Economía.
"En los últimos años se ha acelerado tanto el flujo de información como el de desinformación"
En una segunda prueba, se ha incluido única y exclusivamente las categorías que ocurran un conjunto igual o superior al 10% del total de los datos (AUT, CYS, POL, ECO, SAN) obteniendo unos mejores resultados en la clasificación y obteniendo resultados realmente buenos de verdaderos positivos y verdaderos negativos.
Por otra parte, el equipo de expertos de AyGLOO ha llevado a cabo un análisis comparativo de los distintos modelos NER (Named Entity Recognition) disponibles para determinar cuál es el mejor. Este tipo de modelos detectan en el texto entidades como personas, lugares y organizaciones.
Como la transparencia es otro de los pilares del proyecto, el equipo ha avanzado también en un módulo de explicabilidad para la categorización de un texto de noticia en las secciones más importantes. De forma gráfica se puede ver el sumatorio de probabilidades que decanta una noticia por una sección u otra.
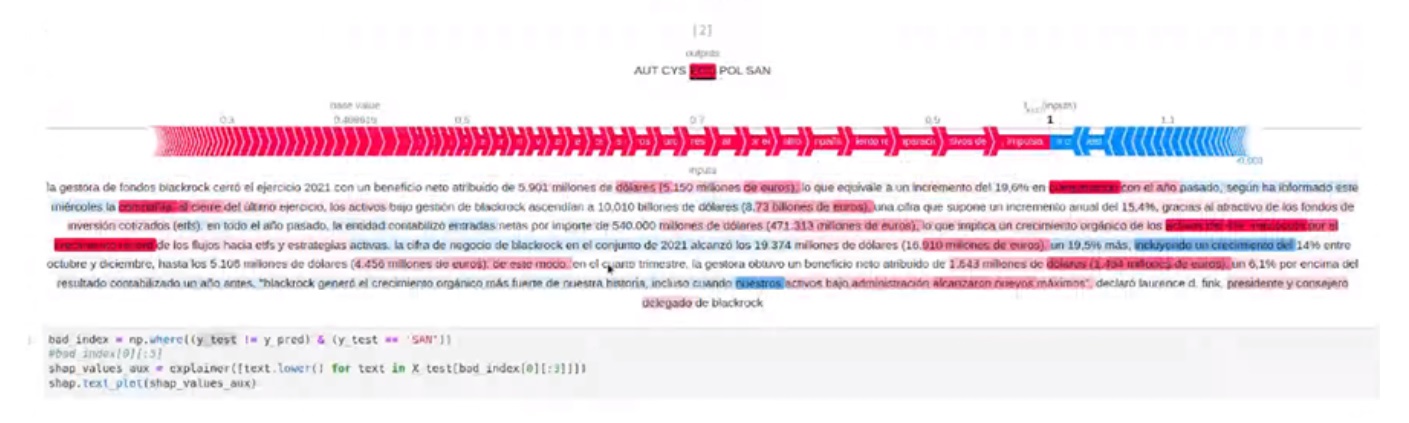
Módulo de explicabilidad desarrollado para el multiclass classification
El corpus de noticias verificadas que alimenta la herramienta incluye aquellas afirmaciones ya comprobadas por alguna entidad de fact checking independiente de todo el mundo. Para ello, se realiza una consulta en la base de datos de Datacommons.org, que han adoptado muchos verificadores de noticias falsas y que también usa en sus resultados de búsqueda Google.
Con este fin, ha sido necesario implementar un proceso de ETL que periódicamente descargue las versiones actualizadas del feed en formato json de la herramienta FactCheck de Datacommons.org, que limpie y prepare la información que utilizaremos para las búsquedas.
Para implementar el motor búsqueda de similitud semántica textual (STS) del que hará uso nuestra API para encontrar hechos verificados, es necesario realizar un proceso de incrustación de texto (text embedding) para representar el contenido semántico de un texto escrito en cualquier idioma en un vector numérico (dense vector) representado en un espacio multidimensional. Para ello, hemos utilizado un modelo para text embedding denominado Sentence-BERT, que realiza incrustaciones de oraciones usando redes siamesas.
Dado que los documentos indexados pueden pertenecer a más de 50 idiomas diferentes, era necesario presentar al usuario resultados de búsqueda en su propio idioma. Para ello se ha incluido el uso de un modelo único de IA creado por Meta AI, el laboratorio de inteligencia artificial que pertenece a Meta Platforms Inc, anteriormente conocido como Facebook, Inc. Ese modelo es el NLLB-200 (No Language Left Behind) que es capaz de traducir con una calidad sin precedentes a 200 idiomas diferentes.
Próximos pasos
Entre los retos para los próximos meses, el desarrollo de un motor de inferencia, módulo de Natural Language Inference (NLI), para recibir y procesar los textos similares de noticias encontrados, continuar con el módulo de explicabilidad y la búsqueda de colaboración con otros organismos y empresas interesados en la lucha contra las fake news.
 Andalucía
Andalucía
 Aragón
Aragón
 Cantabria
Cantabria
 Castilla-La Mancha
Castilla-La Mancha
 Castilla y León
Castilla y León
 Catalunya
Catalunya
 Extremadura
Extremadura
 Galicia
Galicia
 Islas Canarias
Islas Canarias
 Islas Baleares
Islas Baleares
 Madrid
Madrid
 País Vasco
País Vasco
 La Rioja
La Rioja
 C. Valenciana
C. Valenciana
 Navarra
Navarra
 Asturias
Asturias
 Murcia
Murcia
 Ceuta y Melilla
Ceuta y Melilla

.png)