Imágenes generadas por Make-A-Scene - META
MADRID, 14 Jul. (Portaltic/EP) -
Meta ha presentado un prototipo de inteligencia artificial (IA) generativa destinada a complementar la expresividad de los creadores, capaz de crear imágenes más precisas a partir de descripciones de texto en combinación con bocetos.
Descripciones como "un dibujo de una cebra montando en bici" ofrece una base a la IA con la que generar una imagen, pero la composición final es difícil de predecir, con variaciones de posición y tamaño de los elementos que la forman, entre otras posibilidades.
Las descripciones no permiten detallar con exactitud el tamaño de la bicicleta respecto de la cebra ni la posición del manillar, por ejemplo. Para avanzar en este plano, Meta ha presentado 'Make-A-Scene'.
Este sistema de IA se apoya en las descripciones de texto, como otras IA generativas, pero también en los dibujos que hagan las personas, que pueden detallar formas, composiciones o estructuras. La combinación de ambos permite obtener imágenes de mayor calidad, como explica en un comunicado.
En las pruebas de evaluación, la compañía presentó a los participantes dos imágenes generadas por 'Make-A-Scene', una a partir solo de la descripción de texto y otra de la descripción y el boceto, y en ellas ha encontrado que "la imagen generada tanto del texto como del boceto era casi siempre puntuada como mejor alineada con el boceto original", alcanzado este resultado en un 99,54 por ciento de las veces.
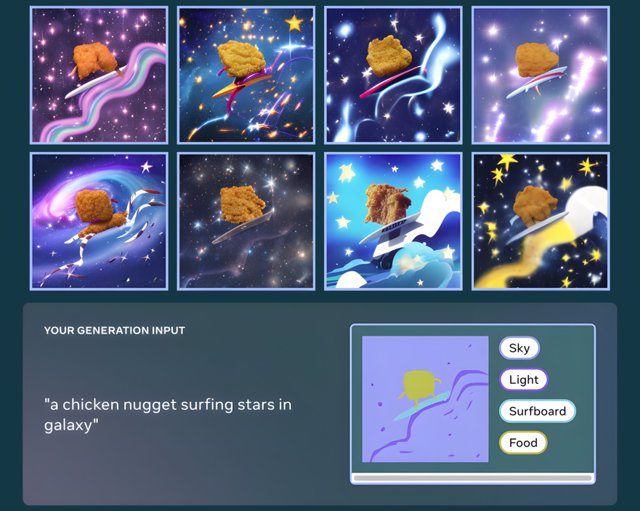
La compañía destaca que en el 66,3 por ciento de las veces la imagen estaba también más alineada con la descripción de texto. "Esto demuestra que las generaciones de Make-A-Scene son de hecho fieles a la visión de una persona comunicada a través del boceto", apunta.
Para entrenar la relación entre elementos visuales y textuales, la compañía ha empleado "millones de imágenes de ejemplo", procedentes de bases de datos públicamente disponibles. El modelo se centra en aprender aspectos clave de las imágenes que tienen más probabilidades de ser importantes para el creador, como objetos o animales.
 Andalucía
Andalucía
 Aragón
Aragón
 Cantabria
Cantabria
 Castilla-La Mancha
Castilla-La Mancha
 Castilla y León
Castilla y León
 Catalunya
Catalunya
 Extremadura
Extremadura
 Galicia
Galicia
 Islas Canarias
Islas Canarias
 Islas Baleares
Islas Baleares
 Madrid
Madrid
 País Vasco
País Vasco
 La Rioja
La Rioja
 C. Valenciana
C. Valenciana
 Navarra
Navarra
 Asturias
Asturias
 Murcia
Murcia
 Ceuta y Melilla
Ceuta y Melilla

.png)